【MySQL】EXPLAINの出力内容と注目すべき点【改善方法】

はじめに
記事の内容が分かりやすくなるようにあらかじめ記事で出てくる語句の説明をします。
- クエリ:特定の情報をデータベースに問い合わせて取得するためのリクエストです。SELECTが当てはまります。
- ステートメント:データベースに対する指示全般を指します。クエリも内包した概念です。"コマンド"もほぼ同じ意味です。
- データベースエンジン:ステートメントを解釈してデータベースと対話をするプログラムです。
それでは本文をどうぞ。
EXPLAINの概要
EXPLAINはクエリがどのように実行される予定なのか(実行計画)を出力してくれるステートメントです。
クエリがデータベースに投げられた後、データベースエンジンは単純に上からレコード探索を始めるのではなく、テーブルの構成・持っている情報・クエリの内容をもとにどのように探索をするかを事前に計画を立てています。そして計画に従って探索が実行されます。
つまりクエリが実行されて取得するまでの流れは以下になります。

実行計画ではデータ取得を最も効率的に行うために以下のようなことを検討しています。
- どのインデックスを利用するか
- どの順番でテーブルを結合するか
- どのように集約をおこなうか
ここで本題のEXPLAINの説明に戻ります。
EXPLAINは実行計画作成のタイミングで処理を終え、データベースエンジンがどのような実行計画を立てたのかを明らかにしてくれるステートメントです。
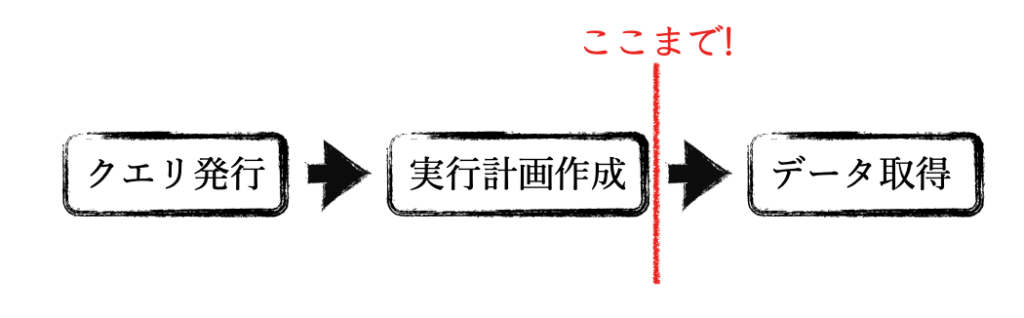
実行計画の作成までであれば、数億のレコードが存在するテーブルに対しての実行でもほぼ一瞬で終わります。そのためクエリ実行に利用できるリソースが限られた環境や大量のデータを処理をする際に、事前にクエリが問題ない処理時間で終わりそうかというパフォーマンスの診断をすることが可能です。
使い方はとてもシンプルで実行したいクエリの頭にEXPLAINをつけるだけです。
// 実行したいクエリ
SELECT * FROM users;
// EXPLAINを使う場合
EXPLAIN SELECT * FROM users;出力結果詳細
ここからはEXPLAINステートメントでどのような項目が出力されるのかを解説します。
実際のEXPLAINステートメントの出力を見てみましょう。
mysql> explain select * from books inner join authors on books.author_id = authors.id;
+----+-------------+---------+------------+--------+---------------+---------+---------+---------------------------------+------+----------+-------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+---------+------------+--------+---------------+---------+---------+---------------------------------+------+----------+-------------+
| 1 | SIMPLE | books | NULL | ALL | author_id | NULL | NULL | NULL | 1 | 100.00 | Using where |
| 1 | SIMPLE | authors | NULL | eq_ref | PRIMARY | PRIMARY | 4 | sample_database.books.author_id | 1 | 100.00 | NULL |
+----+-------------+---------+------------+--------+---------------+---------+---------+---------------------------------+------+----------+-------------+
2 rows in set, 1 warning (0.00 sec)
mysql>EXPLAINステートメントを実行すると表形式で値が返ってきます。この表が実行計画を表しています。
各列の意味について説明します。
id
各クエリに採番されるID。ただクエリを識別するための数字であり、実行される順番を表しているわけではないです。メインとなるクエリは1が割り振られ、サブクエリごとに値は1増えていきます。
基本はサブクエリの実行結果をもとにメインクエリが走るので、数字は大きい方から小さい方向に向かって実行されると考えて良いです。ただしデータベースエンジンによってはクエリ最適化のために順番が前後する可能性があるので、やはりIDはあくまでクエリを識別するための数字とだけ捉えればOKです。
またidはあくまでクエリに対して採番されます。EXPLAINステートメントはクエリが実行されるテーブルごとにレコードが作成されるので、少し上で見せた例では2つのレコードに別れていますがIDは同じです。つまり一つのクエリが二つのテーブルに対してスキャンをしていることになります。
select_type
SQLステートメント全体の中でその行に該当するクエリがどのようなクエリなのかを表すカラムです。代表的なのがPRIMARYとSUBQUERYです。これらは文字通りの意味を持っており分かりやすいです。SIMPLEはUNIONやサブクエリを利用しないシンプルなSELECTであることを指しています。
この値もidと同じく、SQLステートメント内でのクエリの識別情報として利用され、直接改善ポイントを見つけるための値にはなりません。
table
クエリが対象としているテーブルを指しています。単純にテーブルが出力されるだけでなく、サブクエリの結果に対するものであるとかやUNIONで取得した値であるかについても表示してくれます。
partitions
利用するパーティションを指します。パーティションは利用するけどすべてのパーティション、つまりすべてのレコードが探索の対象になるなら"ALL"、特定のパーティションに対してなら"パーティション名"、パーティションが張られていないなら"NULL"を返します。
対象のレコード数が減るのであればクエリ実行にかかる時間は短縮されるのでこの項目は重要なポイントです。後ほど詳細に説明します。
type
単純にtypeというカラム名ですが、MySQLがテーブルをどのように走査もしくは結合しているのかを表す列です。
少しややこしいのですが、カラムでJOIN操作があるときには結合時のインデックスの利用の仕方について、JOIN操作がないときにはJOIN操作以外でのインデックスの利用の仕方(例えばwhere句)についてを表します。
値としては、全てのレコードをスキャンする"ALL"、インデックスを使って特定の範囲のレコードだけスキャンする"range"、インデックスは利用するがすべての行をスキャンする可能性がある"index"などが挙げられます。
インデックスを適切に利用できているのかを表すのでとても重要なカラムです。
possible_keys
そのクエリにて利用できる可能性があるインデックスを表示します。対象はwhere句だけに絞られず、join句やorder by句なども対象にしています。
表示されたインデックスは実際に使うインデックスであるとは限らないということに注意しましょう。あくまで候補です。
実際にクエリが投げられた際には、このインデックスの中から最適なインデックスが選択されて利用されます。
ここがnullだと利用できるインデックスがないことになります。インデックスを利用しているか否かは処理時間に大きく影響を与えるのでこの項目も重要です。
key
MySQLが実際に利用することを決定したインデックスです。possible_keysで表示されるキーはあくまで候補であり、テーブル結合のされ方などによって利用ができなくなる可能性があります。
そのためpossible_keysにインデックスがあっても、keyがnullの場合はインデックスを使わずにクエリ実行されることになってしまいます。
key_len
keyで表示されたインデックスの長さを表しています。
複数カラムからなる複合インデックスを利用しているときに特に重要で、短い場合には本当は複合インデックスの値をすべて使いたいのに半分しか利用できていないということになります。インデックスの長さはカラムのデータ型にもよるので一概に何文字以上あればOKというわけではありません。もし複合インデックスを利用しているのにどう考えてもkey_lenの値が小さいときには、複合インデックスを正しく使えるクエリになっているか再確認すべきでしょう。
ref
keyで選択されたインデックスが張られたカラムの値と比較する値がどのような値かを表した列です。
比較対象が定数であればconst(例:where order_id = 1)、特定のカラムであればカラム名(例:where order_id = order.id)、関数の出力結果であればfuncです。
constは比較が容易なため非常に高速で、逆にfuncは演算処理が入るので低速です。
rows
クエリが結果を得るために調査する必要があるレコード数を表しています。
この値はあくまで最大でどれくらいの行数を調査する必要があるかの推定値であり、実際に調査するレコード数はもっと少なくなることもあります。
調査が必要な行数は処理速度に大きく影響するので重要な項目です。あと単純に値の大小でクエリの負荷がわかるので使いやすいカラムでもあります。
filtered
条件によって全体のレコード数からどれくらいの割合に絞られて出力されるのかを示しています。パーセンテージで表されており、100ならすべてのレコードを出力、50なら半分のレコードを出力、というように見ます。
具体例を挙げます。
以下のように3つのレコードをもつテーブルがあります。
mysql> select * from articles;
+----+--------------+-----------------------+---------------------+
| id | title | content | created_at |
+----+--------------+-----------------------+---------------------+
| 1 | やばいよ | とんでもないよ | 2024-03-13 01:34:51 |
| 2 | 苺 | だいふくだよ | 2024-03-13 01:36:19 |
| 3 | Your | SQL | 2024-03-13 01:36:49 |
+----+--------------+-----------------------+---------------------+
3 rows in set (0.00 sec)
mysql>このテーブルからtitleが"苺"のものにしぼってselectした結果をexplainしてみます。
mysql> select * from articles where title = '苺';
+----+-------+--------------------+---------------------+
| id | title | content | created_at |
+----+-------+--------------------+---------------------+
| 2 | 苺 | だいふくだよ | 2024-03-13 01:36:19 |
+----+-------+--------------------+---------------------+
1 row in set (0.00 sec)
mysql> explain select * from articles where title = '苺';
+----+-------------+----------+------------+------+---------------+------+---------+------+------+----------+-------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+----------+------------+------+---------------+------+---------+------+------+----------+-------------+
| 1 | SIMPLE | articles | NULL | ALL | NULL | NULL | NULL | NULL | 3 | 33.33 | Using where |
+----+-------------+----------+------------+------+---------------+------+---------+------+------+----------+-------------+
1 row in set, 1 warning (0.00 sec)
mysql>33.3と出力されています。3つのレコードが存在するテーブルで、特定のカラムが何か一つの値に絞られたことから1/3の33.3が導かれています。実際にはカラムの型やnot null制約、一意性制約などをもとに総合的に判断してくれています。
この値は単純に全体のレコード数のうちクエリによってどれくらいのレコード数に絞られるのかを表しているかにすぎず、走査対象のレコード数を表しているわけではありません。そのため、この値が1%のような極小さな値になっていても全てのレコードのスキャンが必要な悪いクエリの可能性があることに注意です。
extra
名前の通り、クエリ実行における追加情報を載せています。where句を使っているか(先程の例だとextraに"Using where"とある)だったり、テーブル自体にはアクセスせずインデックスのみを対象に探索することでクエリを完結させられる(Using index)だったり。
あくまで追加情報なので、rowsのように数値の多寡でクエリの良し悪しは判断できず、表示されている情報の意味を知っている必要があります。大量に種類があるのですべては解説しませんが、この後の章で重要な値については解説します。
注目すべきポイント
クエリの最適化をするために特に重要なのは以下の項目です。
- rows
- partitions
- type
- possible_keys
- Extra
そもそも最適なクエリとは「必要な情報のみが得られるかつ処理量が最小のクエリ」です。EXPLAINステートメントでは「処理量を最小にできているか」のヒントを出してくれています。上で挙げた項目は処理量が最小になっているかに大きく影響する項目です。
ここからはそれぞれの項目の値をどのようにクエリ最適化に活かすべきかを説明します。
rows
ここに表示される値が数百万行を超えるような大量の数値であった場合には改善を考える必要があります。
パーティションもしくはインデックスを利用できないか検討しましょう。
最初に説明を持ってきましたが、これはrowsの値がもっとも分かりやすく処理量を表してくれているからです。もしこの値が小さければパーティションやインデックスを利用せずとも基本的に問題はありません。
この値が大きいときに以下で説明するカラムの内容に従ってクエリ最適化を進めるのが良いでしょう。
ちょこっと補足
rowsの値が小さいとしても大量に実行されるクエリであるなら処理量を極限まで減らすべきです。実行回数も考慮した上でクエリの最適化を検討しましょう。
partitions
partitionsの値が"null"もしくは"ALL"の場合にはパーティションが利用されていません。もしテーブルにパーティションを設定しているのであれば、WHERE句での絞り込みに利用してスキャン対象のレコード減らしましょう。
select * from テーブル名 where パーティションが設定されたカラム = 値ちょこっと解説
パーティションが設定されたカラムにはインデックスが張られるわけではないのですが、実質的に同じ機能が付与されます。そのため、通常のWHERE句のようにすべてのレコードをスキャンして条件に合致するものを一つ一つ見つける必要はなく、一気に処理対象のレコードを絞り込むことができます。
type
typeはインデックスを有効活用できているかを示しています。typeの値が"ALL"のときおよび"index"のときにはインデックスが有効活用できていない可能性が高いので改善を検討すべきです。
クエリ実行対象のテーブルに貼られているインデックスを確認し、where句での絞り込みに利用して欲しい情報が得られるのか検討しましょう。
修正後typeの値が以下のような値になったら改善はうまくできていると言えます。
- range:インデックスから範囲を絞って抽出(where id 10 between 19のような)
- ref:インデックスから最大でもひとつの行を抽出( where カラム > 0 のような )
- eq_ref:一つの行同士でインデックスを利用して結合(join table2 on table1.table2_id = table2.id のような。table2.idには一意性制約を設定しているので、一行一行同士での結合になる)
ちょこっと解説
“index"は複合インデックスに使われているカラムのうち一部のカラムのみがクエリに利用されている場合に設定されます。
MySQLは複合インデックスを作成する際にカラムの要素を順番に並べています。例えば firstnameとlastnameという2つのカラムで複合インデックスを作成する場合、「firstname + lastname」という形になります。
具体的には、以下のように設定するとfirstnameが前方に、lastnameが後方に設置されたインデックスがusersテーブルに作成されます。
CREATE INDEX idx_name ON users (firstname, lastname);このときクエリに順番が後ろのlastnameのみを設定した場合にはこの複合インデックスを利用できません。これはMySQLが「左前方一致特性」を持つためです。
複合インデックスをちゃんと使うためには複合インデックスに利用しているカラムをすべてクエリに利用する、もしくは順番が最初のカラムを利用する必要があります。
possible_keys
この値が"NULL"の場合には利用できるインデックスがないことを意味します。クエリの対象となるテーブルのインデックスを確認し、クエリに利用できるか検討しましょう。
Extra
このカラムにはたくさんの値が入ってきますが、特に注意すべき値2つを紹介します。
Using temporary
クエリ実行のために一時的なテーブルを作成することを示しています。一時的なテーブルはメモリに作成されますが、もしサイズが大きすぎる場合にはディスクも利用されることになり、処理に非常に時間がかかってしまいます。
一時テーブルはソート処理やグループ化を行うときなど複雑なクエリを実行する際に利用されます。
対処法としては以下が挙げられます。
- インデックスを利用する:利用するカラムにインデックスが張られていれば一時テーブルなしでクエリ実行できることがあります。
- 不要な句の削除:本当にソート処理グループ化処理が必要な処理なのか検討し、クエリの内容を必要最小限に絞り込みます。
Using filesort
名前にfileとありますがファイルは関係ありません。MySQLは通常ソートバッファという特別なメモリ領域を利用してソートをしていますが、ソートバッファでは処理ができない場合にはメモリやディスクを利用します。
このようにソートバッファではなくメモリやディスクを利用してソートを行う場合にUsing filesortが出力されます。
対処法としては以下が挙げられます。
- インデックスを利用する:ソートに利用するカラムにインデックスが張られていれば一時テーブルなしでソートできることがあります。
- where句を利用する:MySQLではwhereで絞り込まれた後にソートが行われます。ソート対象のレコード数を減らすことでfilesortを防げるかもしれません。ただし今度はwhere句の処理に時間がかかるようになるかもしれないので注意です。最も良い対応方法はソートに利用するカラムにインデックスを作成することです。
まとめ
最後に簡単に良いクエリの作成方法を大雑把にまとめます。
- 必要な情報が何かを検討
- クエリ実行対象のテーブルのインデックスとパーティションの情報を確認
- クエリの検討
- EXPLAINをつけてクエリを実行
- インデックス・パーティションが適切に利用されかやスキャン対象のレコード数を確認
- クエリの改善
- クエリ実行
ここまで読んでいただいた皆さんはわかったと思うのですが、適切なインデックスとパーティションの作成がクエリ最適化にはとても大きく影響します。
どんなインデックスが使えるのか、どのようなパーティションが設定されているのかを把握した上でEXPLAINを実行し、「必要な情報のみが得られるかつ処理量が最小のクエリ」作成職人になりましょう。
ちなみにDB設計をするときにも役立ちます。でも環境でテーブルを作ってみて、思ったようにインデックスやパーティションが使われてクエリが実行されるのか否かをあらかじめ確認しておき、確認が取れてから本番用として採用する、このような手順を踏むことができれば良いDB設計ができるでしょう。