【具体例付き】カバリングインデックスとは?

解説
カバリングインデックスとはクエリに出現するすべてのカラムがインデックスに登録されている状況を指します。SELECT句で取得対象とするカラムやWHERE句で絞り込みに利用するカラムなどすべてのカラムがインデックスに登録されている必要があります。
カバリングインデックスでのクエリ実行は非常に高速です。なぜ高速になるのかを理解するにはインデックスの仕組みを知っている必要があるので簡単に解説します。
まずインデックスとは「索引 + 索引内の探し出したいキーワードにたどり着くためのアルゴリズムおよびデータ構造」です。(詳しくは以前書いたこちらの記事で:【図解】インデックスとは?高速探索を可能にする仕組み【DB】 )
インデックスが設定された状態とは、テーブルの実データとは別の領域にインデックスのデータ構造を構築していることになります。元のテーブルに追加でインデックス用のカラムが追加されるようなイメージではありません。
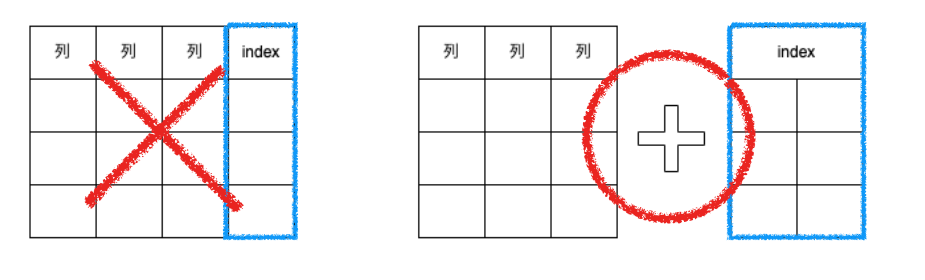
カバリングインデックスでない場合にはインデックスのデータ構造を用いて対象のレコードの位置を把握した後に、テーブルのデータにアクセスする必要があります。つまりインデックスとテーブルという二つの領域にアクセスする必要があります。
カバリングインデックスだと実テーブルにアクセスする必要がなく、インデックスのデータ構造内の探索のみでクエリを完結させることができます。だからこそ高速なクエリ実行が可能になるのです。
インデックス側のデータだけでクエリの全てをカバーできている状態、これがカバリングインデックスです。
ちなみにカバリングインデックスでWHERE句を利用した時のメリットが大きいことは分かると思いますが、WHERE句を使わないSELECTステートメントでもカバリングインデックスは高速で処理負荷も小さくなるので積極的に使うべきです。
これはテーブルよりもインデックスの方がデータサイズが小さく、読み込み処理が容易だからです。(少し深い話をすると、MySQLやPostgreSQLなど多くのリレーショナルデータベースでは単一カラムの値の取得しようとしたときにも一旦行全体を読み込んでいます。これはロウストア型といって各カラムが密接に関わった行として保存されているからです。)
具体例
カラムageとhightで複合インデックスを設定したテーブルusersがあるとします。このテーブルは他にもweightというカラムも持っているとします。
このとき以下のSQLステートメントはどちらもカバリングインデックスになります。
SELECT age, hight FROM users WHERE age = 25;
SELECT age, hight FROM users;逆に以下のSQLステートメントはカバリングインデックスになりません。
SELECT age, hight FROM users WHERE weight = 60;
SELECT age, hight, weight FROM users;weightカラムの情報はインデックスになく、実テーブルへのアクセスが発生してしまうためです。
まとめ
単純にインデックスを活用するだけでも大幅な改善が見込めますが、カバリングインデックスも使いこなすことで一段階上のクエリにできます。このカバリングインデックスは特にレコード数やカラム数が膨大なときに大きな効力を発揮します。
ぜひ使いこなせるようになってください。